A major misconception is that autonomous execution eliminates the need for governance. In reality, AI increases the importance of governance because execution speed compounds architectural mistakes faster than ever. Without governance, AI amplifies chaos. With governance, AI amplifies architecture.
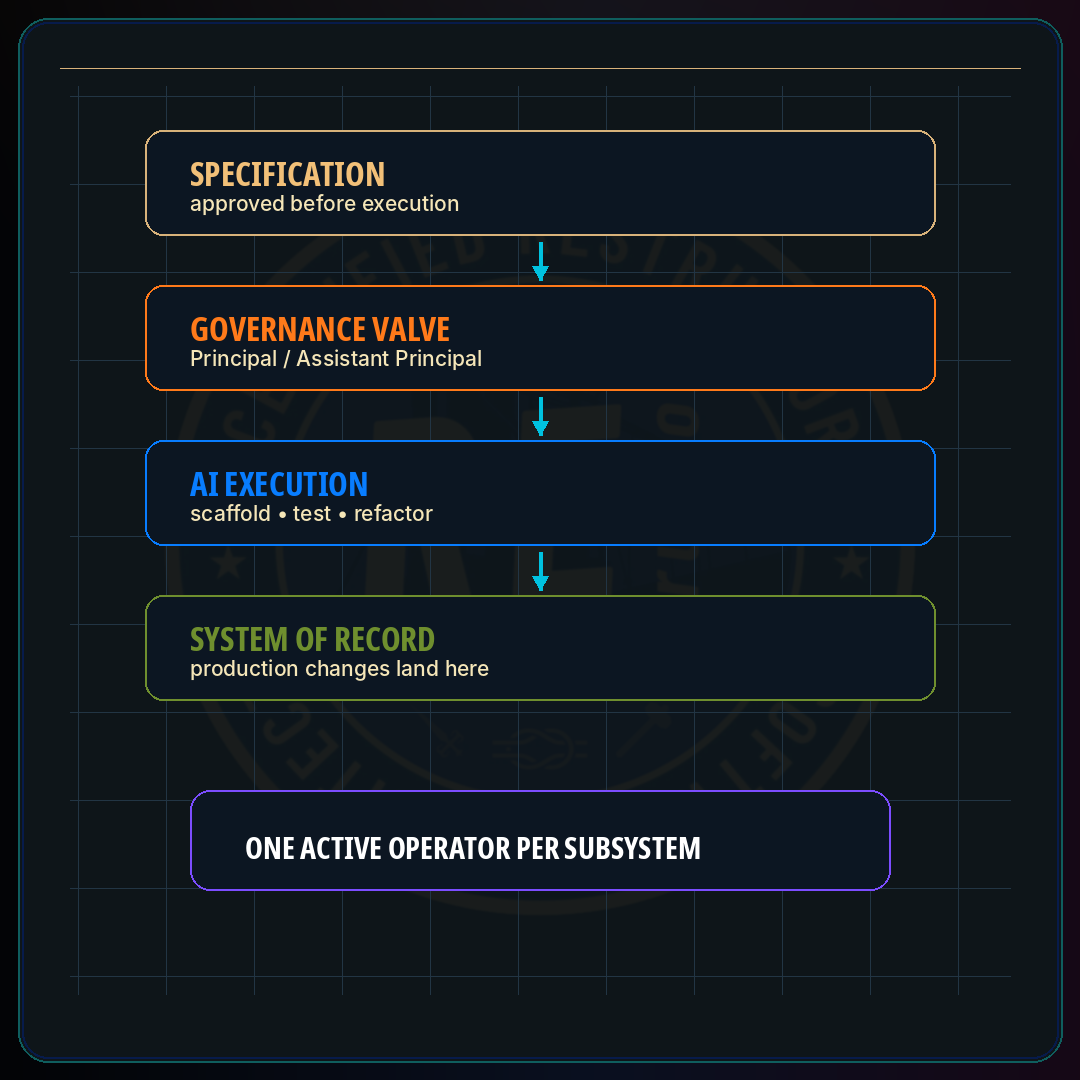
Restruct ™ treats AI as governed execution infrastructure rather than autonomous architectural authority. Principal Architects function as governance valves — execution authorization, architecture review, sequencing, operational boundaries, liability management. AI handles scaffolding, testing, refactoring, debugging, documentation, and operational acceleration. When implementation approaches near-instant, the bottleneck moves upward to judgment, sequencing, and architectural clarity. AI does not eliminate software architects. It elevates them.
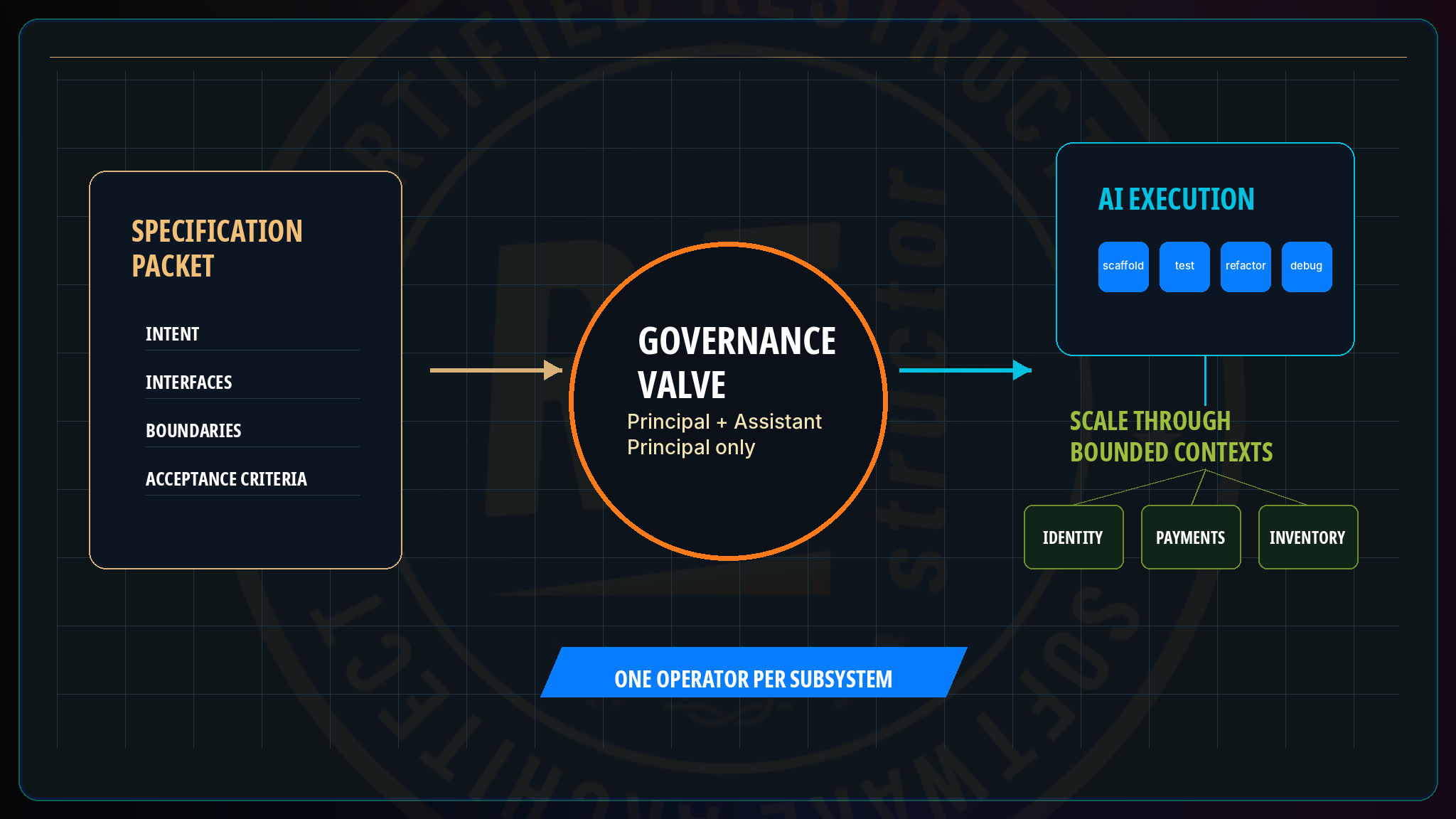
Governance happens before execution
This is also where the strict restriction of AI orchestration to the Principal and Assistant Principal Architect roles earns its keep. The most common objection to that boundary is “why not let five senior engineers orchestrate AI and use PR review as the governance valve?” The answer is that pull request review is the wrong instrument for architectural governance. PR review evaluates code as written ; architectural governance evaluates whether the code should have been written this way at all. By the time AI has generated two thousand lines against the wrong specification, review either rubber-stamps it — because the reviewer is now under-incentivized to demand a redo — or rejects it and burns a day of AI work that could have been prevented by a thirty-minute specification review beforehand. Governance has to happen before execution. It has to be held by the same role authorizing the execution.
Agentic code review services can help with the PR problem, but human-in-the-loop is still necessary at some point. The risk is automation bias : humans relax judgment over time once a machine becomes trusted enough. The pattern is familiar. ATS resume filters were originally designed to solve a simple spam problem — to ease the burden of filtering obviously poor matches. Over time, that automation caused some hiring teams to relax judgment over selection itself, which was never the original intended application.
Authority bias is the same dynamic with higher stakes. Once an AI system carries enough weight in code review, people will begin to over-trust it for decision-making rather than for triage. Governance discipline cannot rely on the machine in the loop; it has to be enforced by the human who owns the decision.
Context as institutional asset
There is also a context-continuity argument worth naming. AI orchestration sessions carry context — the specifications, conventions, and architectural decisions that shape the output. When five people orchestrate AI independently against the same subsystem, the organization accumulates five context windows, none of which share the institutional model of the system. The Principal Architect role is not just a permissions gate; it is a context steward. Unironically, Scrum’s rituals were meant to keep teams in shared product context — a good instinct that struggled because it enforced coherence through ceremony rather than centralized governance. Distributing orchestration distributes context, and distributed context produces incoherent systems regardless of how careful the review is.
This connects directly to the PR queue problem named in Chapter 9. The reason Restruct ™ does not respond to throughput pressure by widening AI orchestration access is that doing so does not actually buy throughput. A single competent Principal Architect orchestrating one AI execution stream against a well-scoped subsystem can already deliver — for known-pattern work — what a conventional team of ten delivered before. Adding a second AI orchestrator to the same subsystem does not double output; it doubles the PR queue feeding the same human review bottleneck, while halving context coherence. The math does not improve. The bottleneck migrates from generation to integration, and integration is the part that does not parallelize.
Scaling through subsystem count
The Restruct ™ answer to “we need more throughput” is therefore structural, not orchestrational. Scaling comes from decomposing the system into more bounded subsystems — SOLID principles applied at the architectural level, Conway’s Law applied deliberately, microservice or modular monolith boundaries drawn where the natural seams are — and standing up N Architecture Groups rather than concentrating N orchestrators in one subsystem. Each Architecture Group has one Principal Architect orchestrating one AI execution stream against one bounded context. Parallelism comes from subsystem count, not from orchestration access. Just as system architecture mirrors team communication structure under Conway’s Law, AI-generated architecture mirrors the structure of AI orchestration access: a system orchestrated by ten people is a ten-author system and reads like an integration project; a system orchestrated by one is a one-author system and reads like a coherent product. The two-role restriction and the “scale through N Architecture Groups” principle from Chapter 13 are the same rule viewed from two angles.
One clarification on what subsystem decomposition means in practice: the methodology is calling for agent-driven domains rather than full microservices. The two are often conflated and they should not be. A bounded subsystem in Restruct ™ means an Architecture Group owns a clear domain — payments, inventory, identity, orchestration — with an AI execution agent scoped to that domain’s code paths and conventions. It does not mandate the operational overhead of a full microservices architecture: separate deployments, network boundaries, independent data stores, service-mesh complexity. A modular monolith with well-scoped agent ownership (“I’m the payments agent, I shouldn’t touch inventory packages”) satisfies the methodology completely. Teams that want microservices for their own operational reasons can have them; teams that do not shouldn’t feel forced by the decomposition argument.
What the boundary does not restrict
One scope clarification is worth making explicit here because it defuses most early objections. The orchestration boundary restricts who can authorize AI-generated changes against the system of record — the production codebase, the governed architecture. It does not restrict who can use AI tools at all. Every engineer in a Restruct ™ organization retains full AI access for their own machines, sandboxes, branches, drafts, exploratory work, learning, prototyping, and the pull requests they themselves author. The boundary is about authorization of changes into the governed system, not about whether engineers may use AI assistance in their daily work. Conflating the two is a common misreading of the methodology and a source of resistance during migration.
Operator versus access. The orchestration boundary restricts who can drive an active AI execution session against the production codebase — Principal Architects and Assistant Principal Architects, the Principal layer of an Architecture Group, which in practice runs one to three people. It does not require that only one specific person ever orchestrate AI within the group. The constraint is one operator at a time, not one person ever. The Principal layer holds the access; any of them can drive an active session, but only one at any given moment, against any given subsystem. This model is an homage to a pattern from the 20th century: terminal-mainframe time-sharing. Until shared-context frameworks mature, the lowest-friction implementation is a remote cloud environment where members of the Principal layer can observe or hand off a single orchestration session — preserving the single-active-operator constraint while removing the single-person bottleneck.
Production authorship and the senior/junior mapping
Pull requests against the production codebase are authored only by Principal Architects, Assistant Principal Architects, and Staff Engineers. Associate Architects do not push directly to main; they work against forks or feature branches where they draft specifications, dry-run them locally against a copy of the system, and surface mid-flight issues before the spec reaches a Principal for review. This keeps the main codebase free of exploratory or partially-formed changes while preserving the Associate’s freedom to experiment, prototype, and learn by doing. The Associate’s output becomes input to a Principal-authored production PR rather than landing directly in the system of record.
The underlying mapping is worth naming explicitly because the industry has been muddled about it for years: Associate Architects are the methodology’s “junior” layer; everyone else (Assistant Principal, Principal, Staff Engineer) is “senior.” Production PRs are touched only by seniors. This dramatically improves the signal-to-noise ratio in the production history and frees Associates from the pressure of authoring code they are not yet ready to govern. The seniority labels “senior” and “junior” can still exist at large scale, but they should only describe experience level — not role function. An experienced Associate Architect is a Sr. Associate Architect; a newly-promoted Principal is a Jr. Principal Architect. Contrast this with the current industry default, where a “Senior Engineer” title might or might not imply architectural responsibility — the same word doing two different jobs, and blurring the line between role and function. Restruct ™ separates the two: role names describe what the person does; seniority modifiers describe how long they have been doing it.
© 2024–2026 Vitruvian Technology, Corp. All rights reserved. The Restruct Handbook and its contents are the copyrighted work of Vitruvian Technology, Corp. The handbook may be freely shared and distributed in its complete, unmodified form for educational and informational purposes, provided that all copyright and trademark notices are retained and Vitruvian Technology, Corp. (Vestive) is credited as the source. Excerpts and brief quotations may be used in articles, reviews, presentations, and other commentary with appropriate attribution. Modification, repackaging, or commercial redistribution requires prior written permission. Restruct™ and Certified Restructor™ are trademarks of Vitruvian Technology, Corp. Vestive® is a registered trademark of Vitruvian Technology, Corp. The Restruct™ methodology, the Certified Restructor™ program, and associated trademarks remain the exclusive property of Vitruvian Technology, Corp.